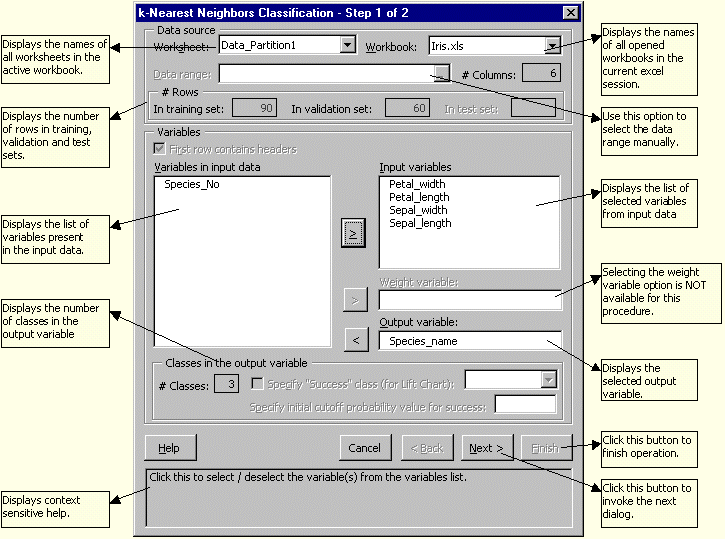
In XLMiner™, select Classification -> k-Nearest Neighbors. In the dialog box that appears, enter the data to be processed, the input variables and the output variable.
Variables: This box lists all the variables present in the dataset. If the "First row contains headers" box is checked, the header row above the data is used to identify variable names. Variables in input data: Select one or more variables as independent variables from the Variables box by clicking on the corresponding selection button. These variables constitute the predictor variables. Output Variable: Select one variable as the dependent variable from the Variables box by clicking on the corresponding selection button. This is the variable being classified. Click Next, and the following dialog box comes up:
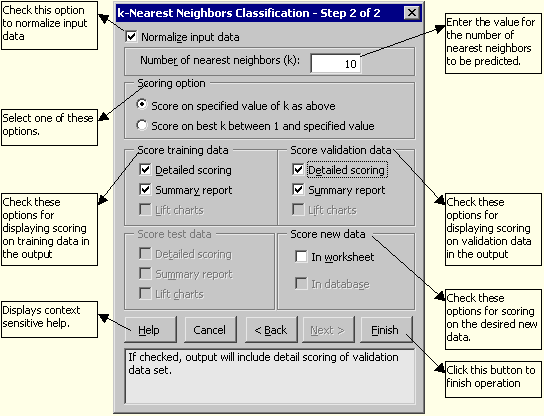
Normalizing the Data: Normalizing the data is important to ensure that the distance measure accords equal weight to each variable -- without normalization, the variable with the largest scale will dominate the measure. Specifying the Number of Nearest Neighbors (k): There is no simple rule for selecting k. If k is too small, the classification of a case (row) could be very sensitive - dependent on the classification of the single case to which it is closest. A larger k reduces this variability, but making k too large introduces bias into the classification decisions. Imagine where k = count of the entire dataset. In this situation, all cases will be classified as the single most populous class. It is usually a good idea to experiment with different values of k, observe the misclassification rate in validation data, and then choose a suitable k. Scoring option : If we select Score on specified value of k as above, the output will be displayed by scoring on the specified value of k. On selecting Score on best k between 1 and specified value, XLMiner™ builds models parallelly on all values of k upto the maximum specified value and scoring is done on the best of these models. Score training data: Select this option to show an assessment of the performance in classifying the training data. The report is displayed according to your specifications - Detailed, Summary and Lift charts. Score validation data: Select this option to show an assessment of the performance in classifying the validation data. The report is displayed according to your specifications - Detailed, Summary and Lift charts. Score Test Data: The options in this group let you apply the model for scoring to the test partition (if one had been created earlier). The option "Score Test Data" is available only if the dataset contains test partition. Select it to apply the model to test data. Score new Data: The options in this group let you apply the model for scoring to an altogether new data. Specify where the new data is located. See the Example of Discriminant Analysis for detailed instructions on this. Score New data in database : See the Example of Discriminant Analysis for detailed instructions on this. |