The following options appear on the Hierarchical Clustering dialogs. See the Common Options section of the Introduction to Analytic Solver Data Science for descriptions of options appearing on the Step 1 of 3 dialog. The Data type argument can be found below.
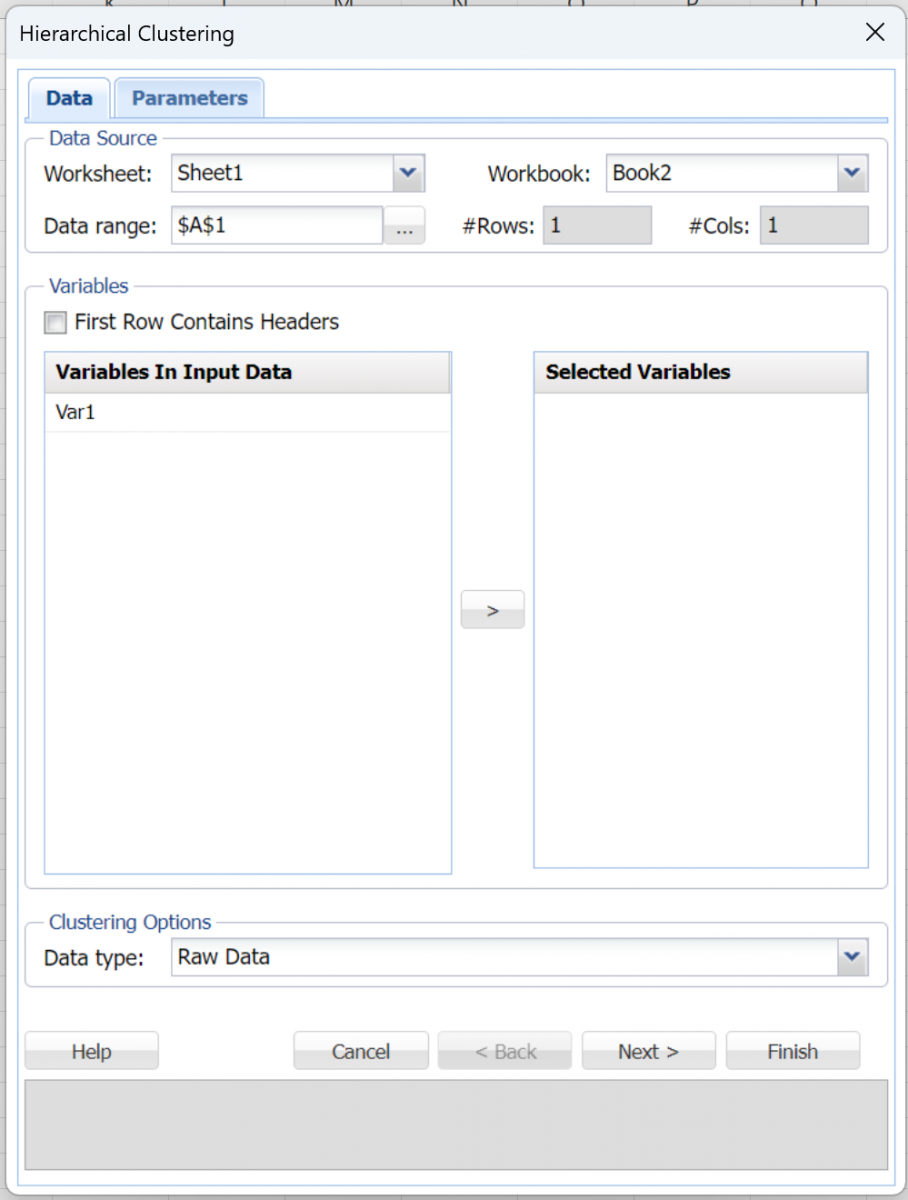
Data Type
The Hierarchical Clustering method can be used on raw data as well as the data in Distance Matrix format. Choose the appropriate option to fit your data set. If Raw Data is chosen, Analytic Solver computes the similarity matrix before clustering.
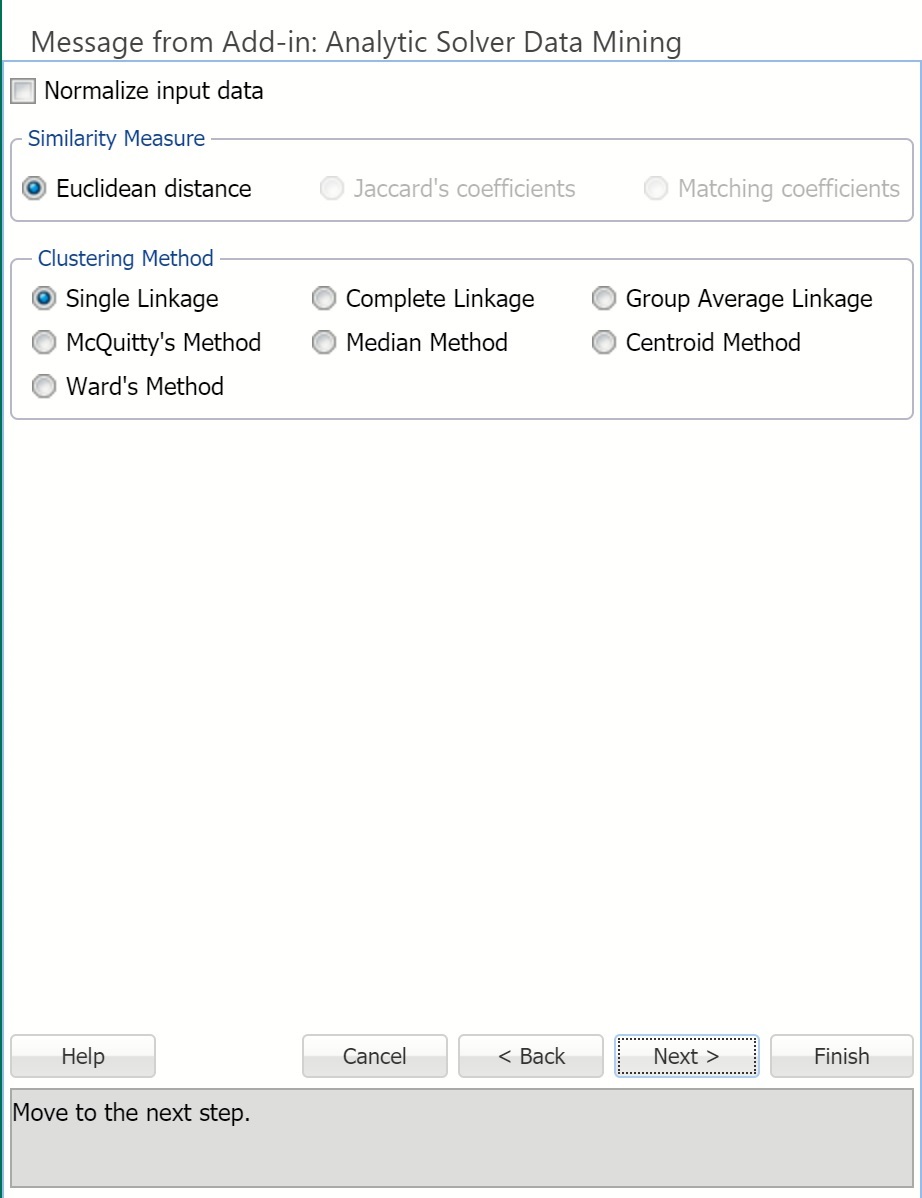
Normalize input data
Normalizing the data is important to ensure that the distance measure accords equal weight to each variable. Without normalization, the variable with the largest scale dominates the measure.
Similarity Measures
Hierarchical Clustering uses the Euclidean distance as the similarity measure for working on raw numeric data. When the data is binary, the remaining two options, Jaccard's coefficients and Matching coefficients, are enabled.
Suppose we have binary values for xij. See the table below for individual i and j values.

The most useful similarity measures in this situation are:
Jaccard's coefficient = d/(b+c+d). This coefficient ignores zero matches.
The matching coefficient = (a + d)/p.
Clustering Method
The goal of clustering is to reduce the amount of data by categorizing or grouping similar data items together. See the introduction to this section for a description of all clustering methods used in Analytic Solver.
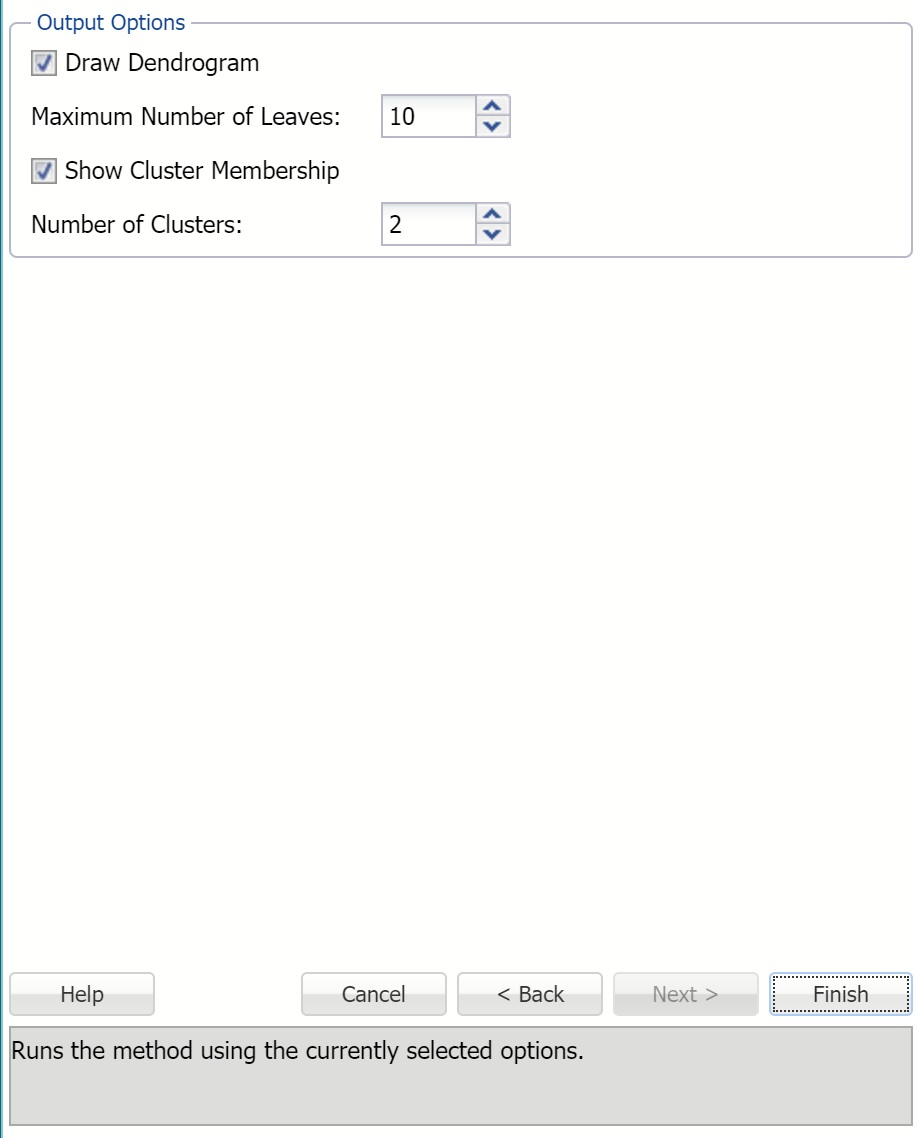
Draw Dendrogram
When this option is selected, Analytic Solver creates a dendrogram to illustrate the clustering process.
Maximum Number of Leaves
If Draw Dendrogram is selected, this option is enabled. Use this option to define the maximum number of leaves in the dendrogram tree. The default setting is equal to 10 or if the number of records in the dataset is less than 10; then the default is the Minimum between the Number of Rows in the dataset and your current licensed limit.
Show cluster membership
Select this option to display the cluster number (ID) to which each record is assigned by the routine.
# Clusters
The agglomerative method of Hierarchical Clustering continues to form clusters until only one cluster is left. Use this option to stop the process at a given number of clusters.